Former Columbia homepage
The original index of research, teaching, software, compression, graphics, and early entrepreneurship materials.

Tech Innovator & Serial Entrepreneur
I create systems that drive technological advances. Before that, I was a professor, researcher and scholar at Columbia University working on data science and Bayesian statistics. I've also had a hand in creating a series of standards in technology, used by billions of people every week: PNG, JPEG-LS, MC-Stan, and deep learning.
Current focus: creating a flow of fresh, high quality data for the world at https://data.flowers.
To predict the future, invent it.
How can a computer come up with new concepts? Can it detect a new meaning of a word? I've solved the long-standing problem of coming up with new concepts automatically, and won the award for the best PhD dissertation granted by the European Association for Artificial Intelligence. This led to deep neural networks, and all the AI we have today: the LLM systems have formed statistical concepts by observing the data of the open world wide web.
It's rare for a new technology to become a successful business, and it's rare for an existing business to successfully develop a lasting technological advantage. I've dedicated my career to straddling between these two domains, and can help businesses bring new technologies to market, and retain their technological edge. I've started several companies, and non-profit organizations both in the US as well as in the EU.
Data is one of the greatest advances in science: it elevates us above the hear-say, and affords us the rigor of science. I've redesigned the course on data science at Columbia University in the City of New York around an applied approach that integrates both machine learning and statistics. I've pioneered the use of data flow user interfaces in data science with the Orange data science platform.
Both AI and humans need up-to-date accurate data. Most data today is still published as content, or fragmented in files. As a result, data doesn't get indexed well, and often gets parsed incorrectly. There are limited incentives to sharing. The data is rarely presented visually.
We'll create tools and protocols for data access, sharing, visualization and analysis, which will lead to the next phase of the internet.
I've served as the chairman of Sledilnik.org that created a COVID-19 dashboard that became the #1 search term on Google in the whole year in a whole country, proving that data can truly go mainstream. As a part of this process, I've developed the concepts of data loops and data excellence that allowed Sledilnik.org to accomplish this feat.

Content commerce is the seamless integration of the ability to buy from encountering an offering within content. 1o has developed embedded e-commerce technology makes this possible, and merged into Katalys to bring these capabilities to the market, raising around $12M to date.
We shipped more than 200,000 pieces of independent paid digital content. We started with a vision for an internet publishing ecosystem based on micropayments, but the industry settled on ads and subscriptions, leading to its continued decline. We adapted our e-commerce technology to support direct sales of content, such as downloads and e-books, working with companies like Sony and authors like Mark Cuban, and pioneered the practice of embedded e-commerce.
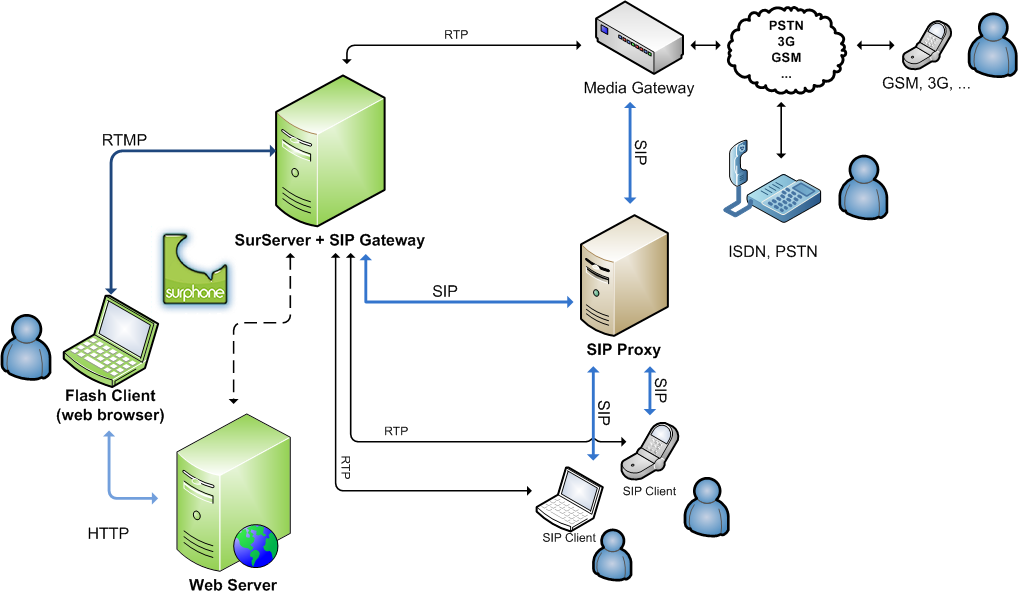
We created a voice-over-ip system that ran inside a website: it was a no-installation voice activation system. This technology was acquired by a system integrator, that then spun it off as a startup that restructured into Layer, which won the TechCrunch Disrupt in 2013 and proceeded to raise around $30M.
With a super-talented international team of developers, we built a game with a state-of-the-art 3D engine for Windows computers. I was responsible for the AI technology, but left as the company pivoted away from games to 3D engines (that were later used for many projects including the GTA franchise). Ironically, Nvidia later acquired Hybrid Graphics, and now AI is a much bigger business for Nvidia than graphics.

Recent writing from Substack, Medium, and earlier essays on AI, data, media, and internet economics.
Inside a conversation on why AI governance is broken and what comes next.
Why open systems often end up serving bad actors unless the good actors defend the commons.
Part 2 of the content economics series: how creators lose out on the value of their data.
Part 1 of the content economics series: how money moved away from content.
The fractal paradigm and the early framing for next-generation digital business.
A framework for understanding the major paths AI can take as it moves into products, systems, and institutions.
How AI expands the engineering frontier by changing what builders can model, automate, and invent.
A look at how the web moved from pages toward mediated environments, and what that means for digital business.
An argument for a more cultivated internet, built around care, growth, and diverse digital spaces.
How crisis coverage can turn attention into anxiety when audiences have little agency to respond.
A media economics essay on how internet distribution reshaped attention, revenue, and publishing incentives.
A proposal for thinking across political categories instead of treating left and right as fixed opposites.
A local mirror of the former Columbia Statistics site has been restored from Archive.org's December 2, 2024 capture. The full mirror is preserved here, with selected entry points below.
The original index of research, teaching, software, compression, graphics, and early entrepreneurship materials.
Interaction analysis papers, dissertation materials, slides, and supporting diagrams.
Models, visualizations, data files, and papers analyzing political voting patterns.
Data mining, Orange, visualization, MDS, and older lecture deck exports preserved as local HTML and PowerPoint files.
A local index of 128 archived Statistical Modeling posts, preserving Archive.org copies with images and comments where captures exist.
JPEG-LS software, JPEG artifact illustrations, wavelet compression demos, and related materials.
Multi-dimensional scaling, real-time vegetation rendering, and earlier visualization projects.
Downloaded locally: 768 Columbia archive files plus 128 Gelman blog post pages. Missing Archive.org captures are noted in the manifests.